── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.2 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsそれでは、1つ前の動画で出題した問題を解説していきます。
Q1: ダイヤモンドの重さと値段の関係を、散布図で描画してください。
データ:diamonds geom:geom_point ->x軸:carat ->y軸:price
ggplot(data = diamonds) +
geom_point(mapping = aes(x = carat, y = price))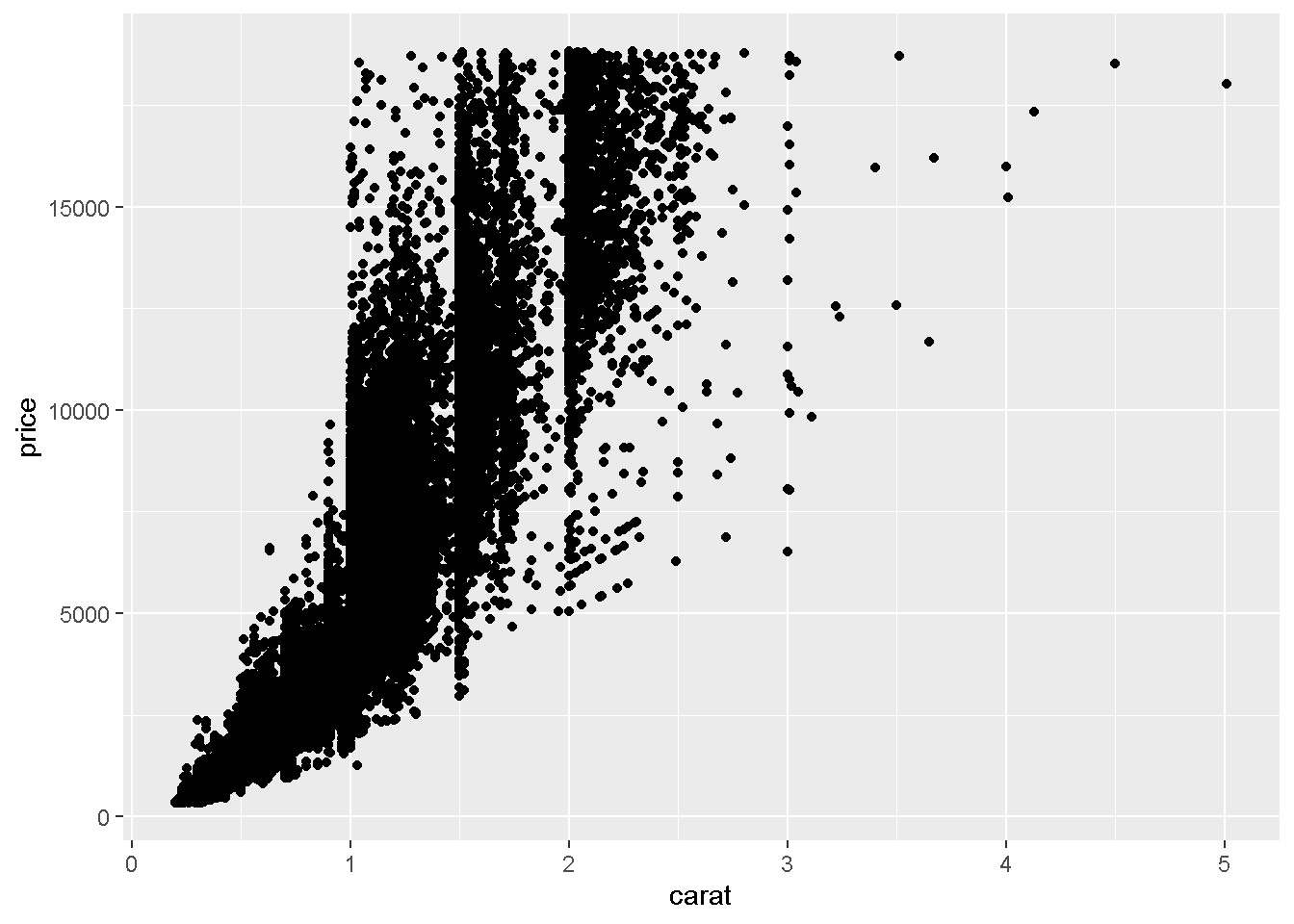
Q2: ダイヤモンドの色と値段の関係を、箱ひげ図で描画してください。
データ:diamonds geom:geom_boxplot ->x軸:color ->y軸:price
ggplot(data =diamonds) +
geom_boxplot(mapping = aes(x = color, y = price))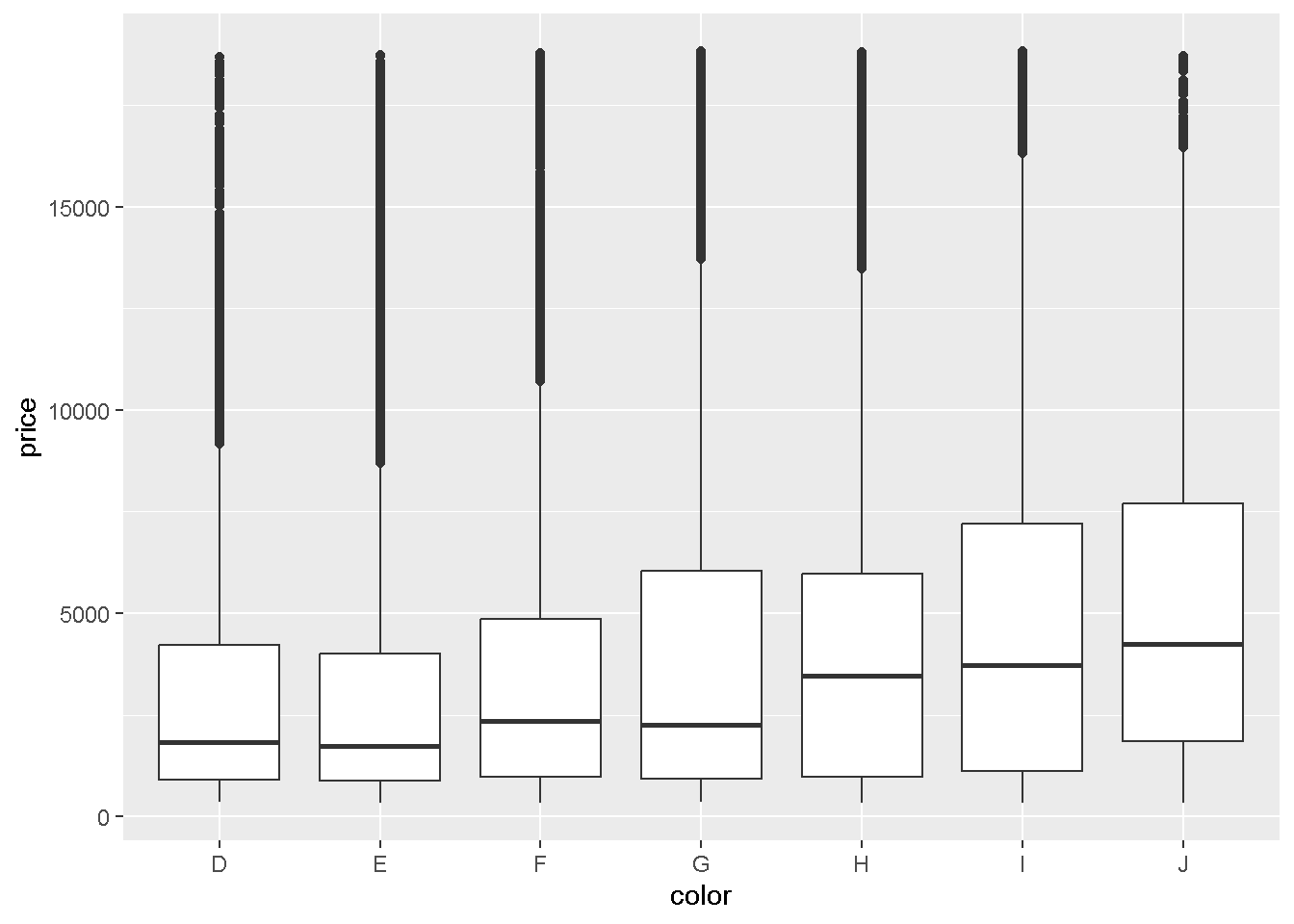
Q3: ダイヤモンドの透明度と色の関係を、何らかの形で描画してください
データ:diamonds geom: ??? ->x軸:clarity ->y軸:color
ここでは、x軸とy軸がそれぞれカテゴリカル変数 なので、これまでお伝えした関数の中で利用できる geomはgeom_countです。
gdia <- ggplot(data = diamonds)
gdia + geom_count(aes(clarity, color))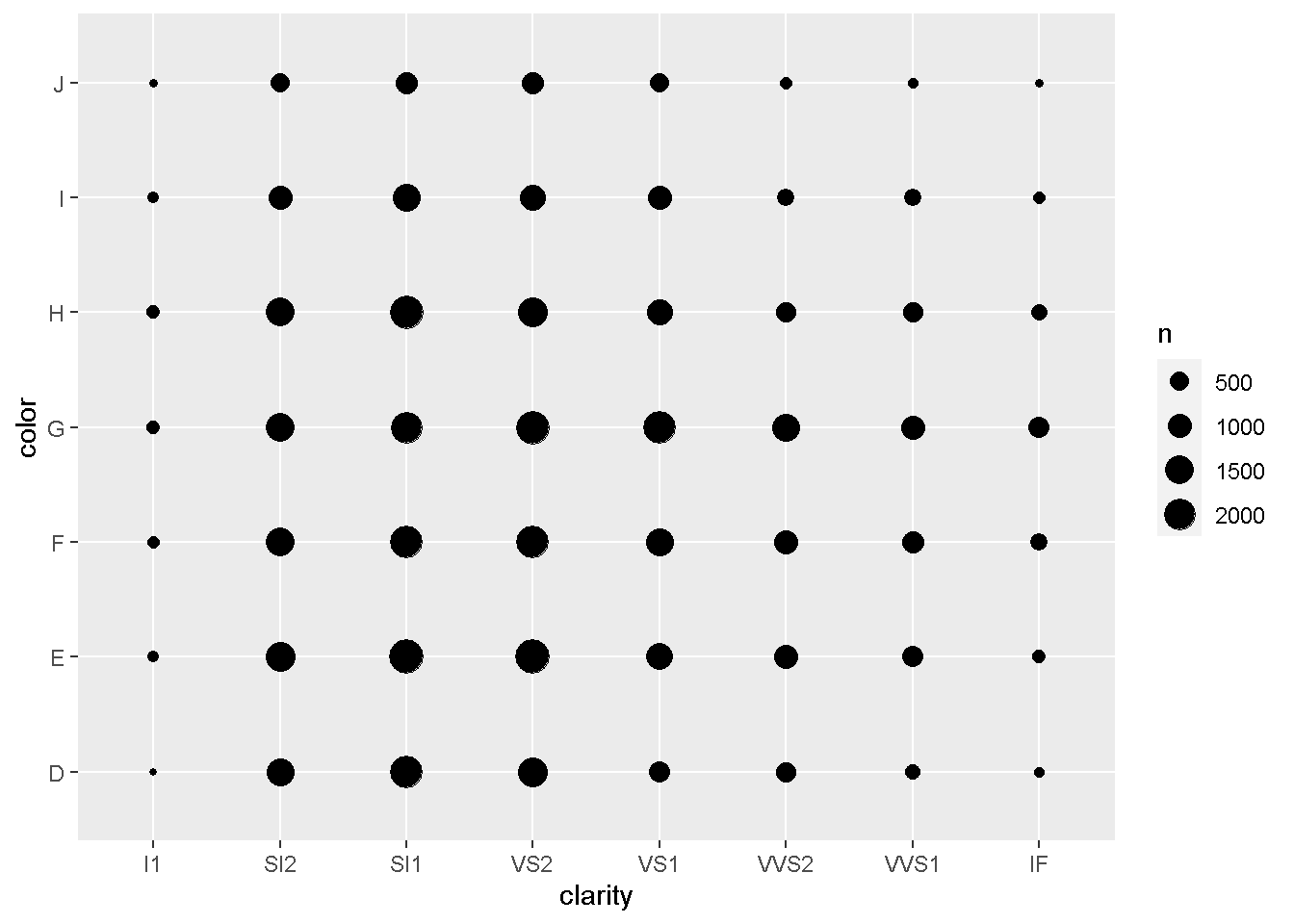
他にも、カテゴリカル×カテゴリカルで利用できる geomは、geom_jitterというものがあり、
gdia + geom_jitter(aes(clarity, color))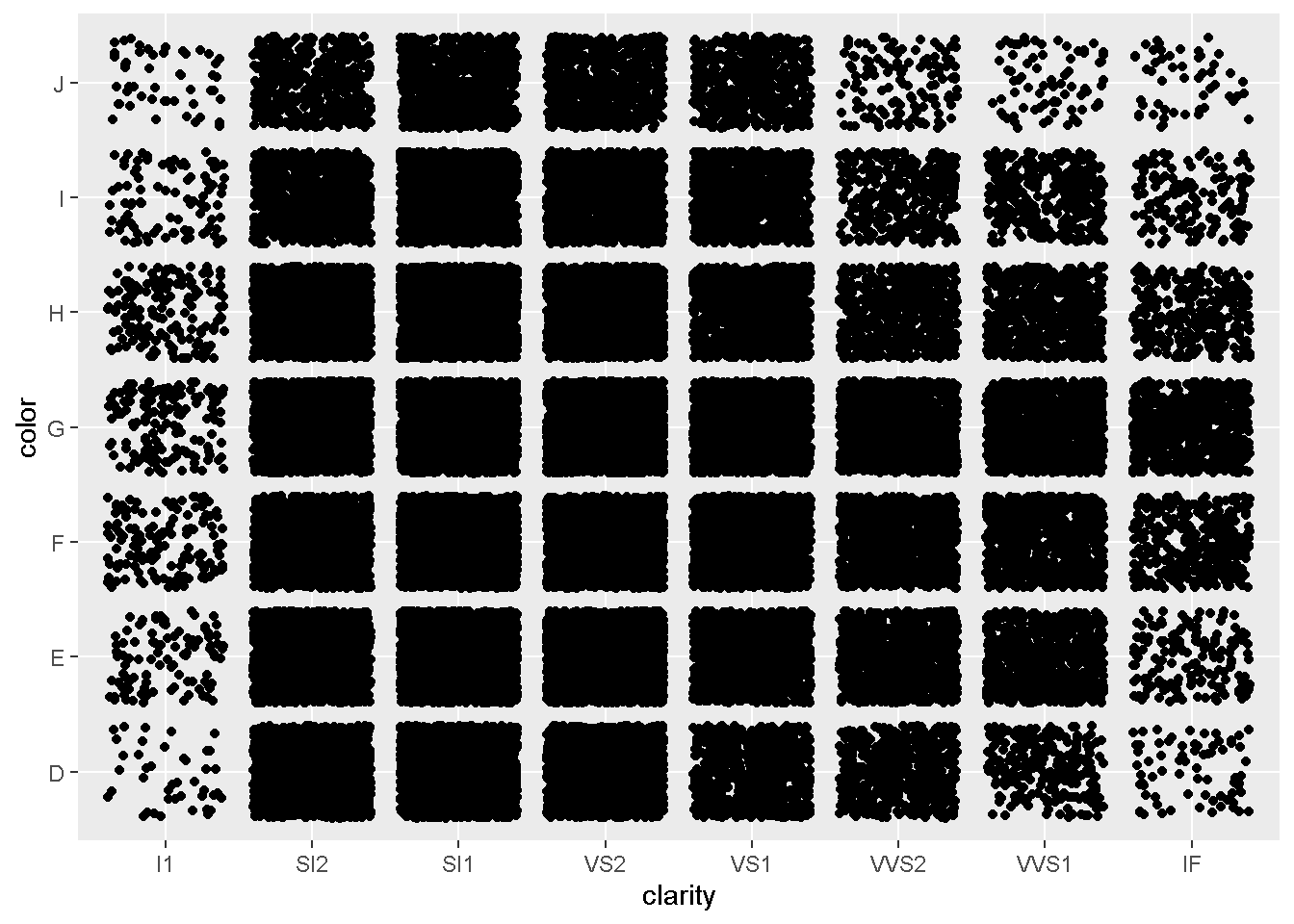
こんな感じで、gdiaという変数を作っておくと、 別のgeomを適応する場合も、それほど手間なく 描画できます。
今回、jitterが見やすいとは思いませんが、 それぞれのカテゴリに含まれる数がそれほど 多くない場合に、どれくらいのデータの個数が 含まれているかを直観的に把握できるので、 覚えておいてもよいかもしれません。
Q4: ダイヤモンドの値段の分布を ヒストグラムにして描画してください
データ:diamonds geom: geom_histogram ->x軸:price ->y軸:集計
gdia + geom_histogram(aes(price))`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.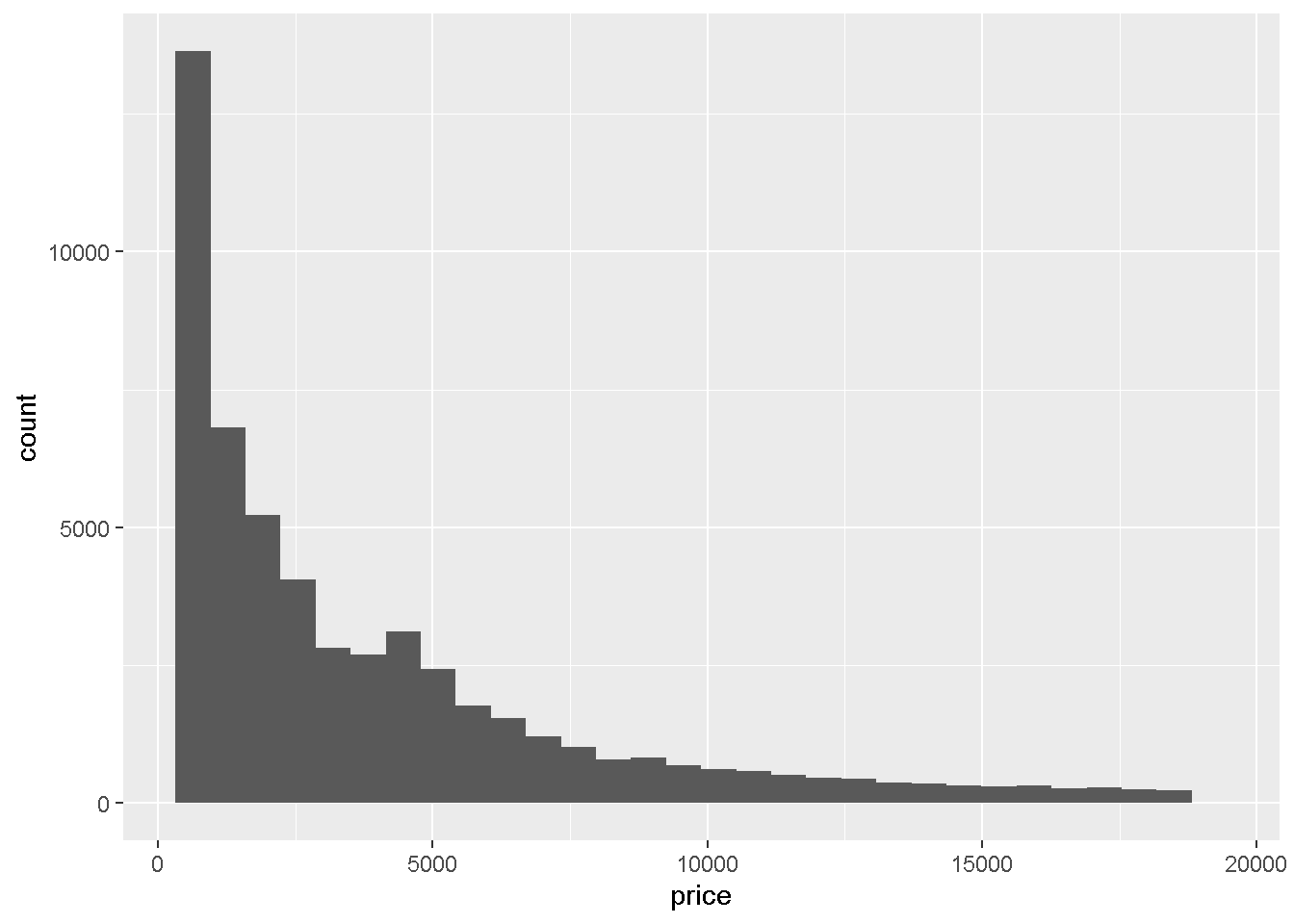
Argumentから全部書き出すとこんな感じです:
ggplot(data = diamonds) +
geom_histogram(mapping = aes(x = price))`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.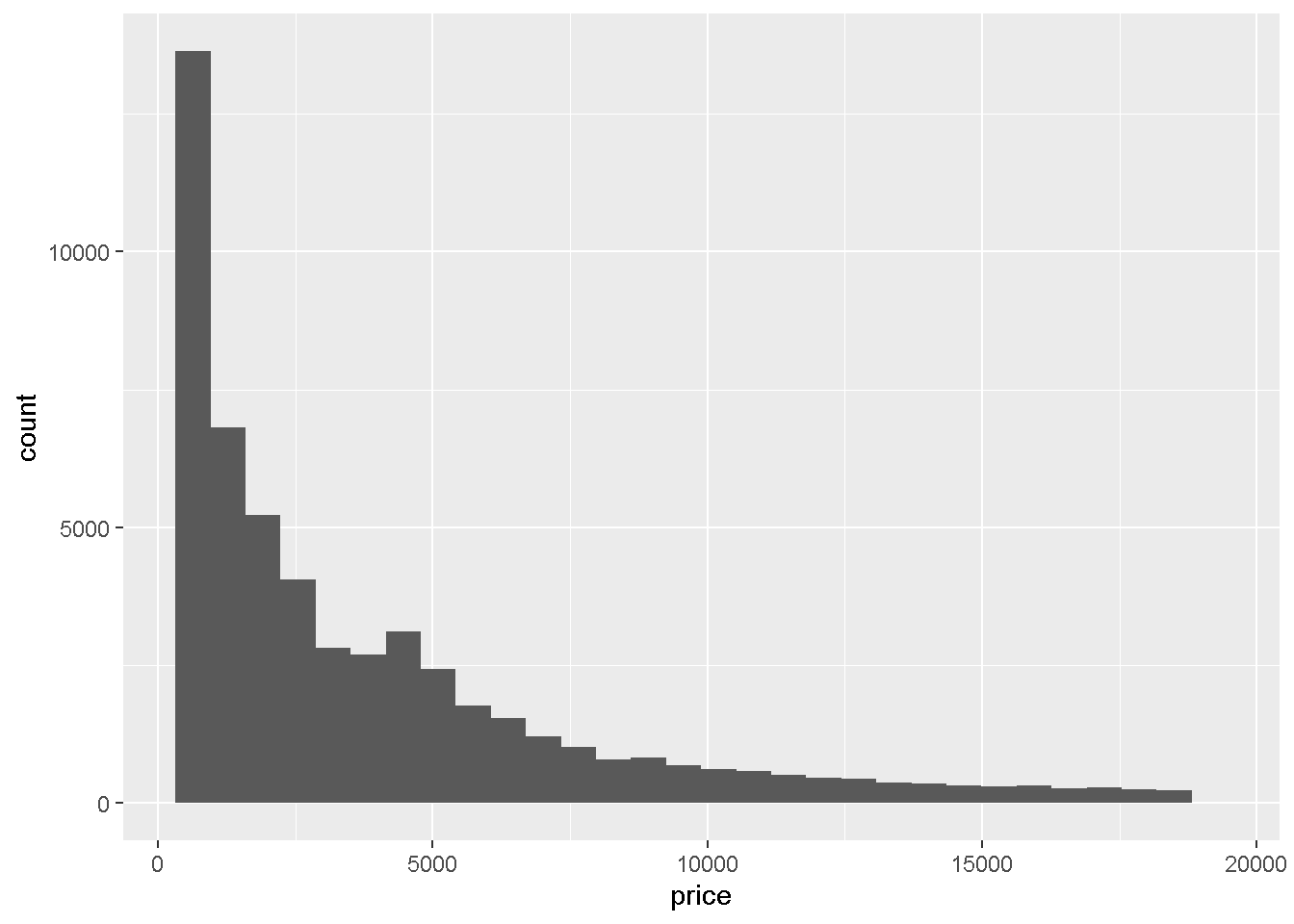
Q5: ダイヤモンドのカットの質が分類毎に、このデータセットに何件ずつあるのかを描画してください。
データ:diamonds geom:geom_bar ->x軸:cut ->y軸:集計
gdia + geom_bar(aes(cut))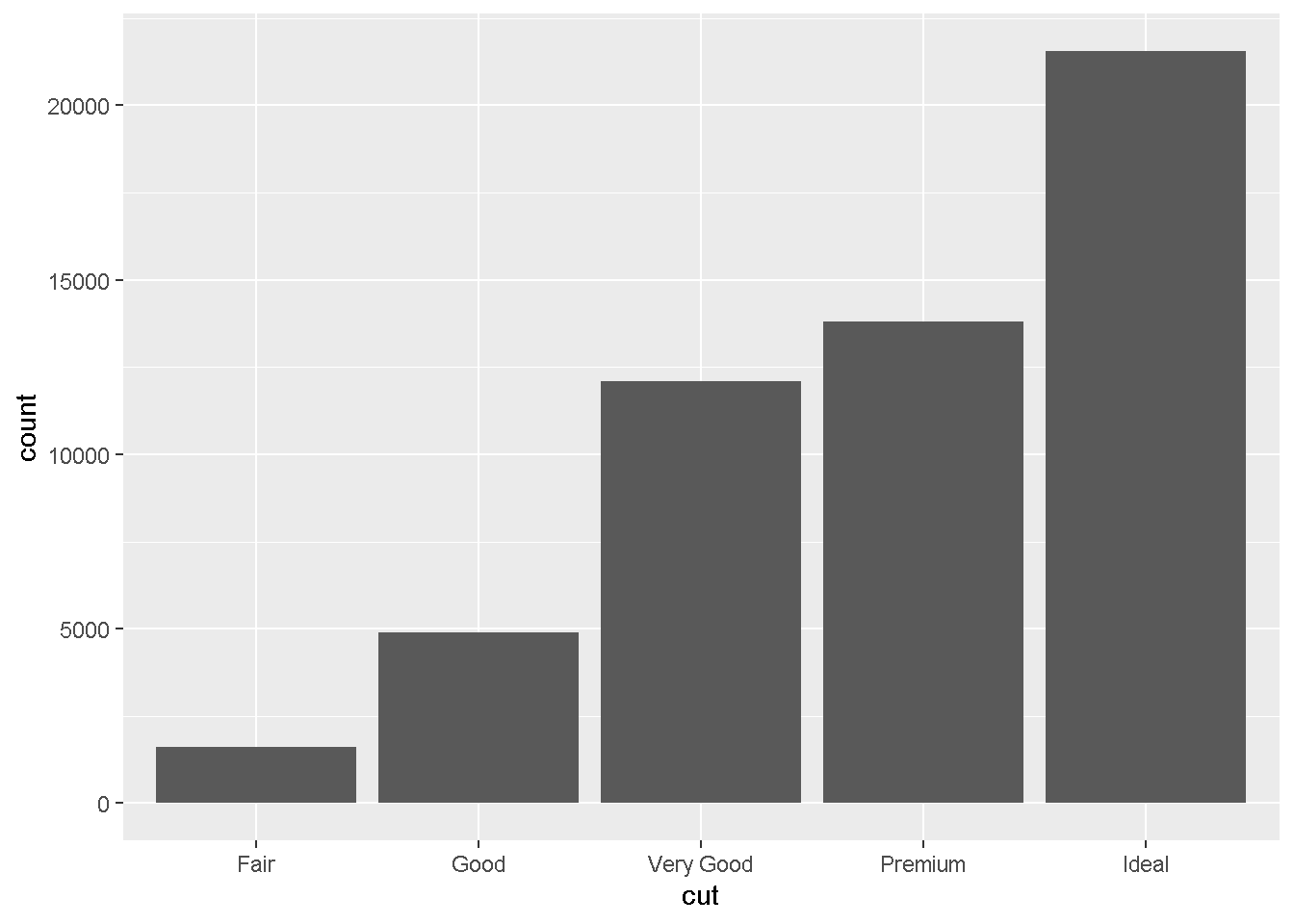
summary(diamonds$cut) Fair Good Very Good Premium Ideal
1610 4906 12082 13791 21551 直接集計結果をsummary関数などで見た方が正確な数字わかりますが、geom_bar関数で集計されていること、みていただけるかと思います。
Q6: この問題には、economicsデータを利用します。米国の失業者数の推移を何らかの形で描画してください。
データ:economics geom:??? ->x軸:date ->y軸:unemploy
ここでは、x軸はdateという日付型の変数です。日付型の変数はまだ解説していませんが、現時点では連続変数の一種であるというような理解でOKです。
推移を表現するので、利用できるgeomにはgeom_line等を使ってみましょう。
economics# A tibble: 574 × 6
date pce pop psavert uempmed unemploy
<date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1967-07-01 507. 198712 12.6 4.5 2944
2 1967-08-01 510. 198911 12.6 4.7 2945
3 1967-09-01 516. 199113 11.9 4.6 2958
4 1967-10-01 512. 199311 12.9 4.9 3143
5 1967-11-01 517. 199498 12.8 4.7 3066
6 1967-12-01 525. 199657 11.8 4.8 3018
7 1968-01-01 531. 199808 11.7 5.1 2878
8 1968-02-01 534. 199920 12.3 4.5 3001
9 1968-03-01 544. 200056 11.7 4.1 2877
10 1968-04-01 544 200208 12.3 4.6 2709
# ℹ 564 more rowsg_eco <- ggplot(economics)
g_eco + geom_line(aes(date, unemploy))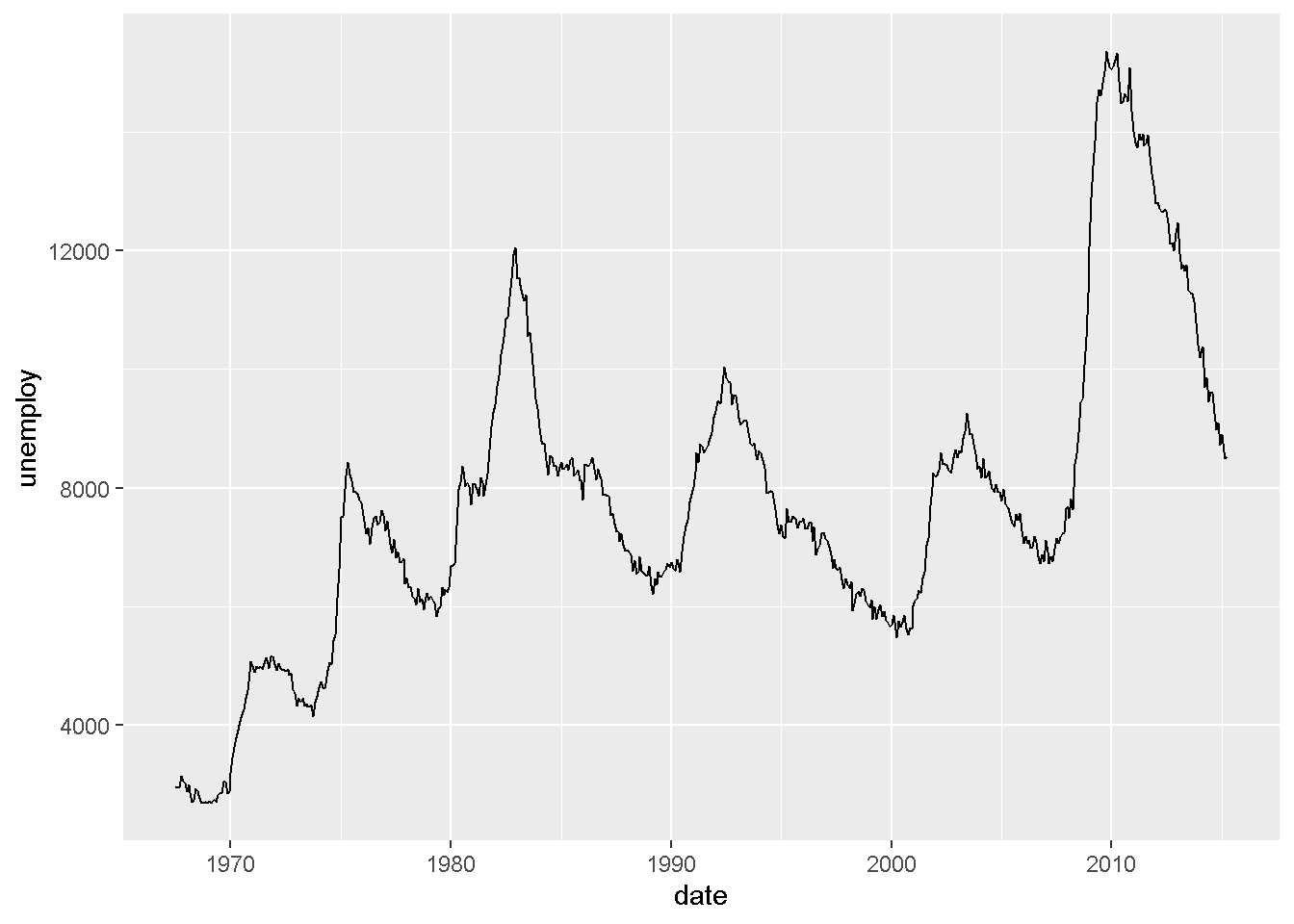
他にも、点を打つだけでも大丈夫かもしれません
g_eco + geom_point(aes(date, unemploy))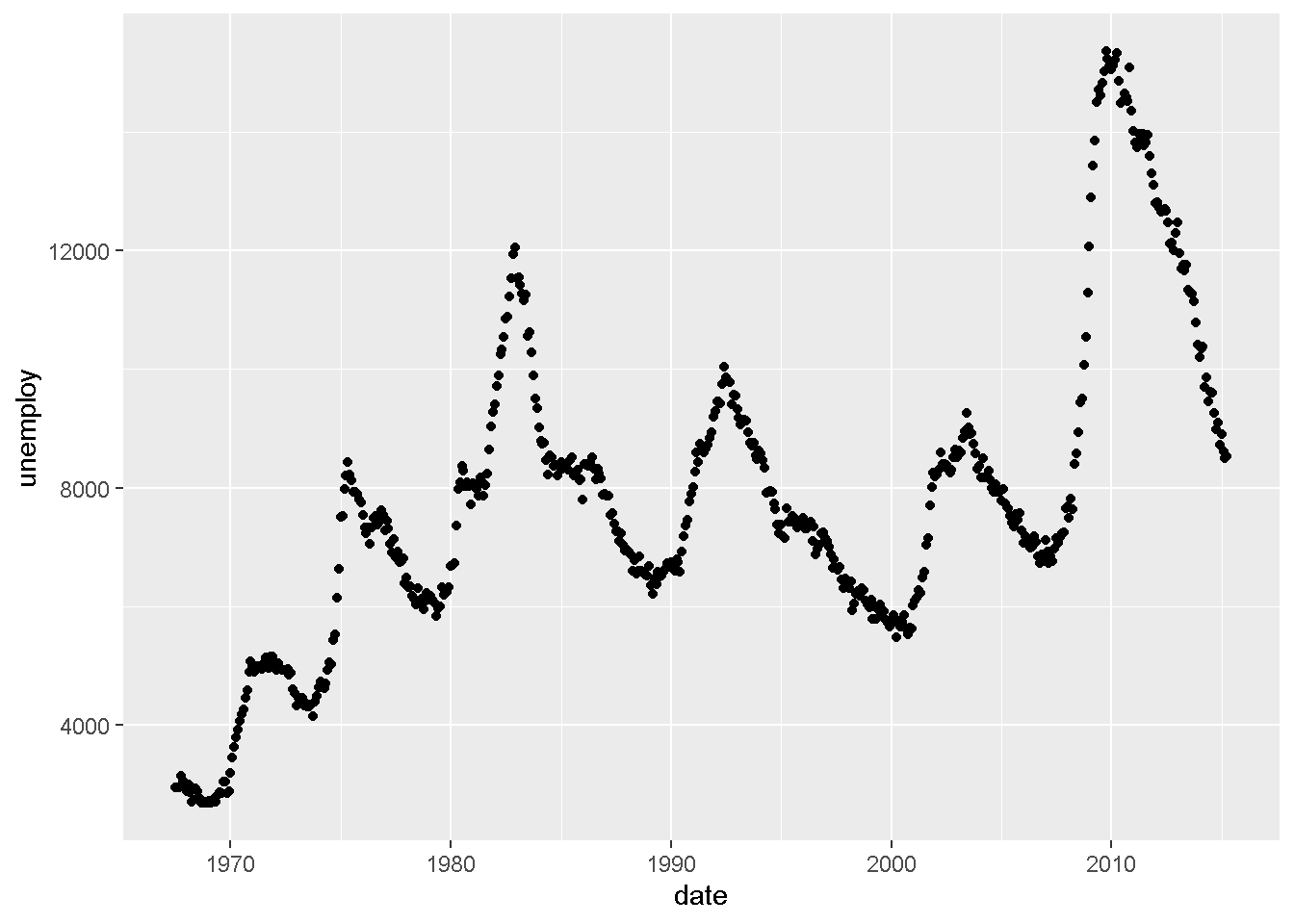
以上、ggplot+geom_xxxの基本的な形の解説と演習でした。
次の動画からは第3、第4の軸、色や形の設定などについて解説していきます。