library(tidyverse)それでは練習問題を解いていきましょう。
問題1
whoデータを縦持ちデータにしてください。データの説明は、?whoで見ることができます。
問題2
data/to_wider.csvにあるデータは、whoの日本の部分のデータを縦にしたデータです。このデータを、元の形の横持ちにしてください。
問題1
whoデータを縦持ちデータにしてください。
library(tidyverse)
dat <- whoさて、このデータですが、列名を確認すると、
colnames(dat) [1] "country" "iso2" "iso3" "year" "new_sp_m014"
[6] "new_sp_m1524" "new_sp_m2534" "new_sp_m3544" "new_sp_m4554" "new_sp_m5564"
[11] "new_sp_m65" "new_sp_f014" "new_sp_f1524" "new_sp_f2534" "new_sp_f3544"
[16] "new_sp_f4554" "new_sp_f5564" "new_sp_f65" "new_sn_m014" "new_sn_m1524"
[21] "new_sn_m2534" "new_sn_m3544" "new_sn_m4554" "new_sn_m5564" "new_sn_m65"
[26] "new_sn_f014" "new_sn_f1524" "new_sn_f2534" "new_sn_f3544" "new_sn_f4554"
[31] "new_sn_f5564" "new_sn_f65" "new_ep_m014" "new_ep_m1524" "new_ep_m2534"
[36] "new_ep_m3544" "new_ep_m4554" "new_ep_m5564" "new_ep_m65" "new_ep_f014"
[41] "new_ep_f1524" "new_ep_f2534" "new_ep_f3544" "new_ep_f4554" "new_ep_f5564"
[46] "new_ep_f65" "newrel_m014" "newrel_m1524" "newrel_m2534" "newrel_m3544"
[51] "newrel_m4554" "newrel_m5564" "newrel_m65" "newrel_f014" "newrel_f1524"
[56] "newrel_f2534" "newrel_f3544" "newrel_f4554" "newrel_f5564" "newrel_f65" こんな感じです。 少し厄介なのが、newの後に、sp, sn, ep, relとついていて、その後に性別と年齢がついているデータなのですが、newrelだけなぜかアンダースコアがついていないため、separateで簡単に分けるというわけにはいかなさそうです。
とりあえず、pivot_longerを実行してみましょうここで、colsに指定するものはnewではじまる列です
names_toとvalues_toは”name”と”value”としておきましょう。
tate <- dat %>%
pivot_longer(
cols = !c(country, iso2, iso3, year),
names_to = "name",
values_to = "value"
)とりあえず、先ほどcolnames(dat)で確認しましたが、ここでnewで始まっていた列名をベクトルで取り出してunique関数で一意のものにして見てみましょう。
tate$name %>% unique() [1] "new_sp_m014" "new_sp_m1524" "new_sp_m2534" "new_sp_m3544" "new_sp_m4554"
[6] "new_sp_m5564" "new_sp_m65" "new_sp_f014" "new_sp_f1524" "new_sp_f2534"
[11] "new_sp_f3544" "new_sp_f4554" "new_sp_f5564" "new_sp_f65" "new_sn_m014"
[16] "new_sn_m1524" "new_sn_m2534" "new_sn_m3544" "new_sn_m4554" "new_sn_m5564"
[21] "new_sn_m65" "new_sn_f014" "new_sn_f1524" "new_sn_f2534" "new_sn_f3544"
[26] "new_sn_f4554" "new_sn_f5564" "new_sn_f65" "new_ep_m014" "new_ep_m1524"
[31] "new_ep_m2534" "new_ep_m3544" "new_ep_m4554" "new_ep_m5564" "new_ep_m65"
[36] "new_ep_f014" "new_ep_f1524" "new_ep_f2534" "new_ep_f3544" "new_ep_f4554"
[41] "new_ep_f5564" "new_ep_f65" "newrel_m014" "newrel_m1524" "newrel_m2534"
[46] "newrel_m3544" "newrel_m4554" "newrel_m5564" "newrel_m65" "newrel_f014"
[51] "newrel_f1524" "newrel_f2534" "newrel_f3544" "newrel_f4554" "newrel_f5564"
[56] "newrel_f65" 先ほどと同様ですが、このデータをうまく分割する必要があります。
newrelのところを踏まえると、今回はextract関数を利用しましょう。
tate2 <- tate %>%
extract(name, c("new","type","sex","age"), regex="(new_|new)(.+)_(m|f)(\\d+)")
tate2 %>% count(new)# A tibble: 2 × 2
new n
<chr> <int>
1 new 101360
2 new_ 304080tate2 %>% count(type)# A tibble: 4 × 2
type n
<chr> <int>
1 ep 101360
2 rel 101360
3 sn 101360
4 sp 101360tate2 %>% count(sex)# A tibble: 2 × 2
sex n
<chr> <int>
1 f 202720
2 m 202720tate2 %>% count(age)# A tibble: 7 × 2
age n
<chr> <int>
1 014 57920
2 1524 57920
3 2534 57920
4 3544 57920
5 4554 57920
6 5564 57920
7 65 57920それぞれ、extractで分割した列の内訳をみると、問題なく取得できているようです。
ただ、new列は必要ありませんので、最後に消しておきましょう。
tate3 <- tate2 %>%
select(!new)
tate3# A tibble: 405,440 × 8
country iso2 iso3 year type sex age value
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan AF AFG 1980 sp m 014 NA
2 Afghanistan AF AFG 1980 sp m 1524 NA
3 Afghanistan AF AFG 1980 sp m 2534 NA
4 Afghanistan AF AFG 1980 sp m 3544 NA
5 Afghanistan AF AFG 1980 sp m 4554 NA
6 Afghanistan AF AFG 1980 sp m 5564 NA
7 Afghanistan AF AFG 1980 sp m 65 NA
8 Afghanistan AF AFG 1980 sp f 014 NA
9 Afghanistan AF AFG 1980 sp f 1524 NA
10 Afghanistan AF AFG 1980 sp f 2534 NA
# ℹ 405,430 more rowsここまでをまとめて書いてあげると
dat %>%
pivot_longer(
cols = !c(country, iso2, iso3, year),
names_to = "name",
values_to = "value"
) %>%
extract(name, c("new","type","sex","age"), regex="(new_|new)(.+)_(m|f)(\\d+)") %>%
select(!new)# A tibble: 405,440 × 8
country iso2 iso3 year type sex age value
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan AF AFG 1980 sp m 014 NA
2 Afghanistan AF AFG 1980 sp m 1524 NA
3 Afghanistan AF AFG 1980 sp m 2534 NA
4 Afghanistan AF AFG 1980 sp m 3544 NA
5 Afghanistan AF AFG 1980 sp m 4554 NA
6 Afghanistan AF AFG 1980 sp m 5564 NA
7 Afghanistan AF AFG 1980 sp m 65 NA
8 Afghanistan AF AFG 1980 sp f 014 NA
9 Afghanistan AF AFG 1980 sp f 1524 NA
10 Afghanistan AF AFG 1980 sp f 2534 NA
# ℹ 405,430 more rowsこれ、extract部分はpivot_longerの中に入れることが可能なので、この変換、
long_res <- dat %>%
pivot_longer(
cols = !c(country, iso2, iso3, year),
names_to = c("new","type","sex","age"),
values_to = "value",
names_pattern = "(new_|new)(.+)_(m|f)(\\d+)"
) %>%
select(!new)という風に書いてあげることも可能です!
以上、回答でした。
おまけに、
gdat <- long_res %>%
filter(iso3 == "JPN") %>%
filter(sex == "m") %>%
filter(type == "sp") %>%
filter(!is.na(value))
ggplot(gdat) +
geom_point(aes(x = year, y = value, color = age)) +
geom_line(aes(x = year, y = value, color = age, group=age))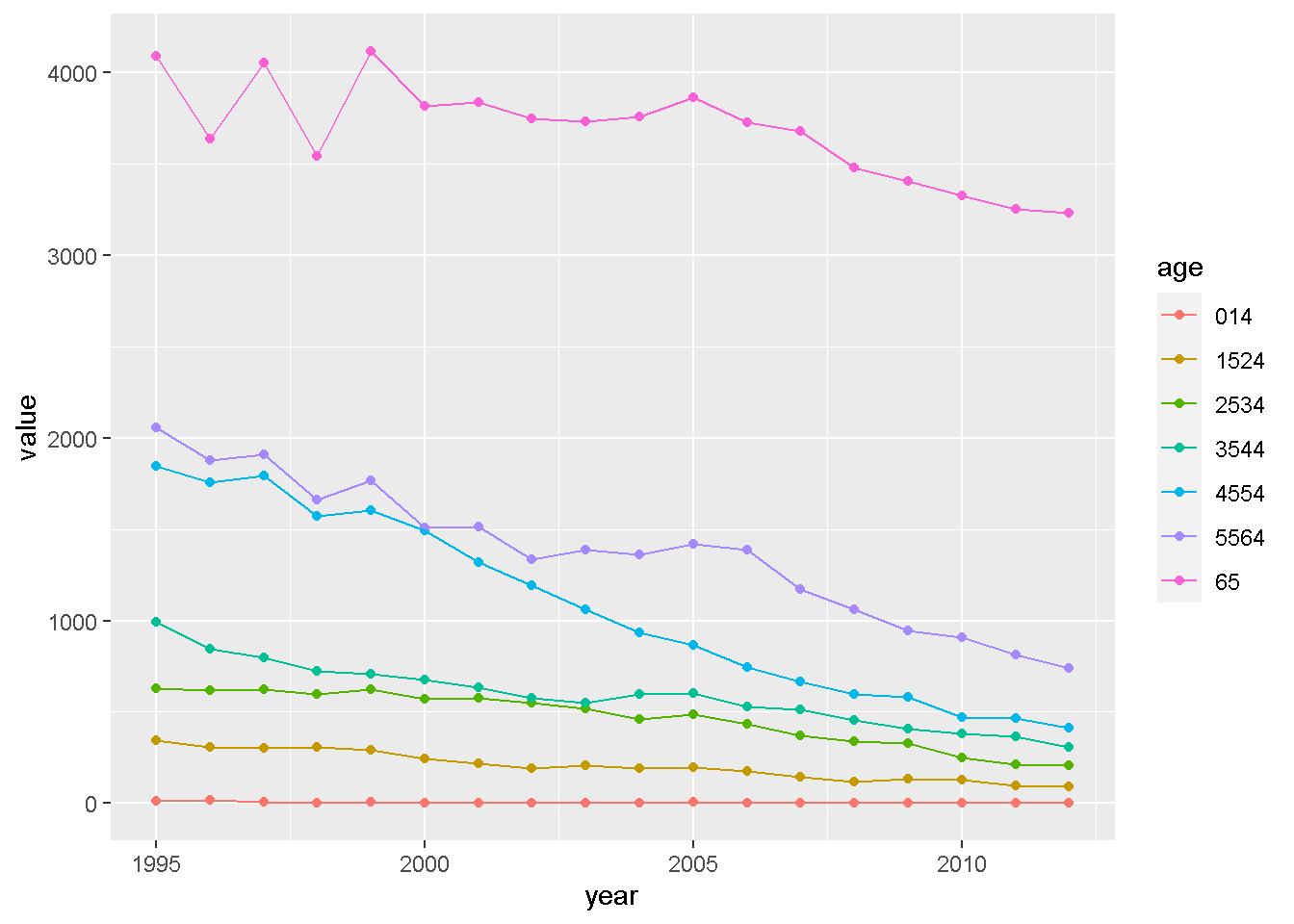
日本の男性のspを年代別にプロットするとこんな感じです。geomを二つ重ねる書き方は解説しておりませんが、ggplotの中級レベルのコースでまた解説いたします。
問題2
data/to_wider.csvのデータを横持ちにしてください。
この、to_wider.csvのデータ、一つ前の問題の最後のgdatの内容を保存したものです。
dat <- read_csv("data/to_wider.csv")Rows: 126 Columns: 8
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (6): country, iso2, iso3, type, sex, age
dbl (2): year, value
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.dat# A tibble: 126 × 8
country iso2 iso3 year type sex age value
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl>
1 Japan JP JPN 1995 sp m 014 15
2 Japan JP JPN 1995 sp m 1524 342
3 Japan JP JPN 1995 sp m 2534 627
4 Japan JP JPN 1995 sp m 3544 995
5 Japan JP JPN 1995 sp m 4554 1847
6 Japan JP JPN 1995 sp m 5564 2059
7 Japan JP JPN 1995 sp m 65 4089
8 Japan JP JPN 1996 sp m 014 16
9 Japan JP JPN 1996 sp m 1524 309
10 Japan JP JPN 1996 sp m 2534 621
# ℹ 116 more rows元にもどしていきましょう。
とは言っても基本的な使い方を行うだけなので、それほど難しくありません。
dat %>%
pivot_wider(id_cols = c(country, iso2, iso3, year),
names_from = c(type, sex, age),
values_from = value,
names_sep = "_")# A tibble: 18 × 11
country iso2 iso3 year sp_m_014 sp_m_1524 sp_m_2534 sp_m_3544 sp_m_4554
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Japan JP JPN 1995 15 342 627 995 1847
2 Japan JP JPN 1996 16 309 621 843 1756
3 Japan JP JPN 1997 8 304 625 798 1793
4 Japan JP JPN 1998 2 306 597 724 1571
5 Japan JP JPN 1999 6 290 623 706 1605
6 Japan JP JPN 2000 2 246 572 676 1494
7 Japan JP JPN 2001 3 220 576 632 1319
8 Japan JP JPN 2002 2 191 549 579 1192
9 Japan JP JPN 2003 1 210 521 550 1063
10 Japan JP JPN 2004 2 193 462 599 934
11 Japan JP JPN 2005 9 197 488 605 868
12 Japan JP JPN 2006 3 175 436 529 743
13 Japan JP JPN 2007 1 142 372 512 668
14 Japan JP JPN 2008 2 117 339 456 599
15 Japan JP JPN 2009 1 134 328 410 580
16 Japan JP JPN 2010 1 128 252 382 469
17 Japan JP JPN 2011 0 96 215 367 465
18 Japan JP JPN 2012 2 94 209 309 415
# ℹ 2 more variables: sp_m_5564 <dbl>, sp_m_65 <dbl>いかがでしょうか?
お疲れさまでした、このセクション、後もう一つ、データをくっつけるという概念の解説をおこなったら最終問題を行ってすべて終了となります。